







デスクトップでの作業を自動化するために RPA (Robotic Process Automation) が広く知られています。しかしブラウザを通じた Web アプリケーションの操作であれば、ブラウザとサーバー間の通信を模倣するだけで再現することができます。例えば特定のフォームに値を入力して送信するような操作や、Web ページから値を抽出するスクレイピングのような操作は、上記の方法で実現できます。
本稿ではブラウザ画面を用いて行う作業を、Kompira Enterprise を用いて通信を模倣することにより自動化します。具体的には Web サイトから内容を取得して表示する方法をご紹介します。
HTML ファイルを扱うために Python のライブラリである Beautiful Soup4 を使用します。ライブラリの使用に関しては「Python で記述された処理を Kompira Enterprise から呼び出す」にて紹介しています。このライブラリを用いて本コラムのタイトル一覧を取得します。
※ 本稿は Kompira Enterprise 1.6系に準拠した画像を用いています。
動作確認環境
本稿は、以下の環境で検証しています。
| ソフトウェア | バージョン |
|---|---|
| Kompira Enterprise | 1.5.5.post11 |
| OS | CentOS 7.8.2003 |
または
| ソフトウェア | バージョン |
|---|---|
| Kompira Enterprise | 1.6.2.post4 |
| OS | CentOS 7.8.2003 |
または
| ソフトウェア | バージョン |
|---|---|
| Kompira Enterprise | 1.6.8 |
| OS | CentOS Stream 8 |
Python ライブラリの準備
まず Python ライブラリである BeautifulSoup4 をインストールします。Kompira Enterprise では /opt/kompira/bin/pip を使用してライブラリをインストールすることができます。
それでは、Kompira Enterprise サーバーにログインし、次のコマンドを用いてインストールしてください。
$ sudo /opt/kompira/bin/pip install beautifulsoup4
インストール後、次のコマンドを実行しインストールを確認してください。
$ /opt/kompira/bin/pip show beautifulsoup4 Name: beautifulsoup4 Version: 4.12.2 Summary: Screen-scraping library ・・・
HTML リソースの取得
まず Kompira Enterprise の組み込み関数である urlopen() を使い、HTTP リクエストを送信して結果を取得します。urlopen() の詳細に関しては「簡単な Web サーバーの監視をする」にて紹介しています。今回は Kompira Enterprise の運用自動化コラムのページの HTML リソースを取得するので、次のジョブフローを作成し HTML リソースが取得できることを確認します。
| url = "https://www.kompira.jp/column" | urlopen(url, quiet=true) -> [response = $RESULT] -> [status_code = response.code] -> print(status_code) # code=200であれば取得成功
取得に成功していた場合、200が表示されます。
Kompira Enterprise ライブラリの作成
ここでは、コラムページからタイトル一覧を取得するライブラリを作成します。ライブラリは、HTML リソースを取得するジョブフローと同じ階層に KompiraWebpageAnalyzer という名前で作成します。
ブラウザ付属のツールを用いてウェブページの内容を確認します。ここでは Chrome のデベロッパーツールを使って取得しています。

「[事前準備] 接続先のサーバを登録する」というタイトルは次のような内容であることがわかります。
<ul class="list-column"> <li><a href="https://www.kompira.jp/column/prepare_registration_host/">[事前準備] 接続先のサーバを登録する</a></li> // 以下、省略 </ul>
タイトルに関係する HTML タグ情報がわかったので、以下のようなライブラリを作成します。
from bs4 import BeautifulSoup
def get_title_table(html):
title_table = list()
soup = BeautifulSoup(html, 'html.parser')
for ul in soup.find_all('ul', class_="list-column"):
for li in ul.find_all('li'):
title_table.append(li.a.text)
return title_table
タイトル一覧の取得
作成したライブラリを使用して、タイトル一覧を取得し表示するジョブフローを次のように作成します。
| url = "https://www.kompira.jp/column" |
urlopen(url, quiet=true) ->
[response = $RESULT] ->
# HTML コンテンツのみを抽出
[html_body = response.body] ->
# タイトル一覧取得
[./KompiraWebpageAnalyzer.get_title_table: html_body] ->
[title_table = $RESULT] ->
{ for title in title_table |
print(title)
}
実行に成功すれば、以下のようにコラムのタイトル一覧が表示されます。
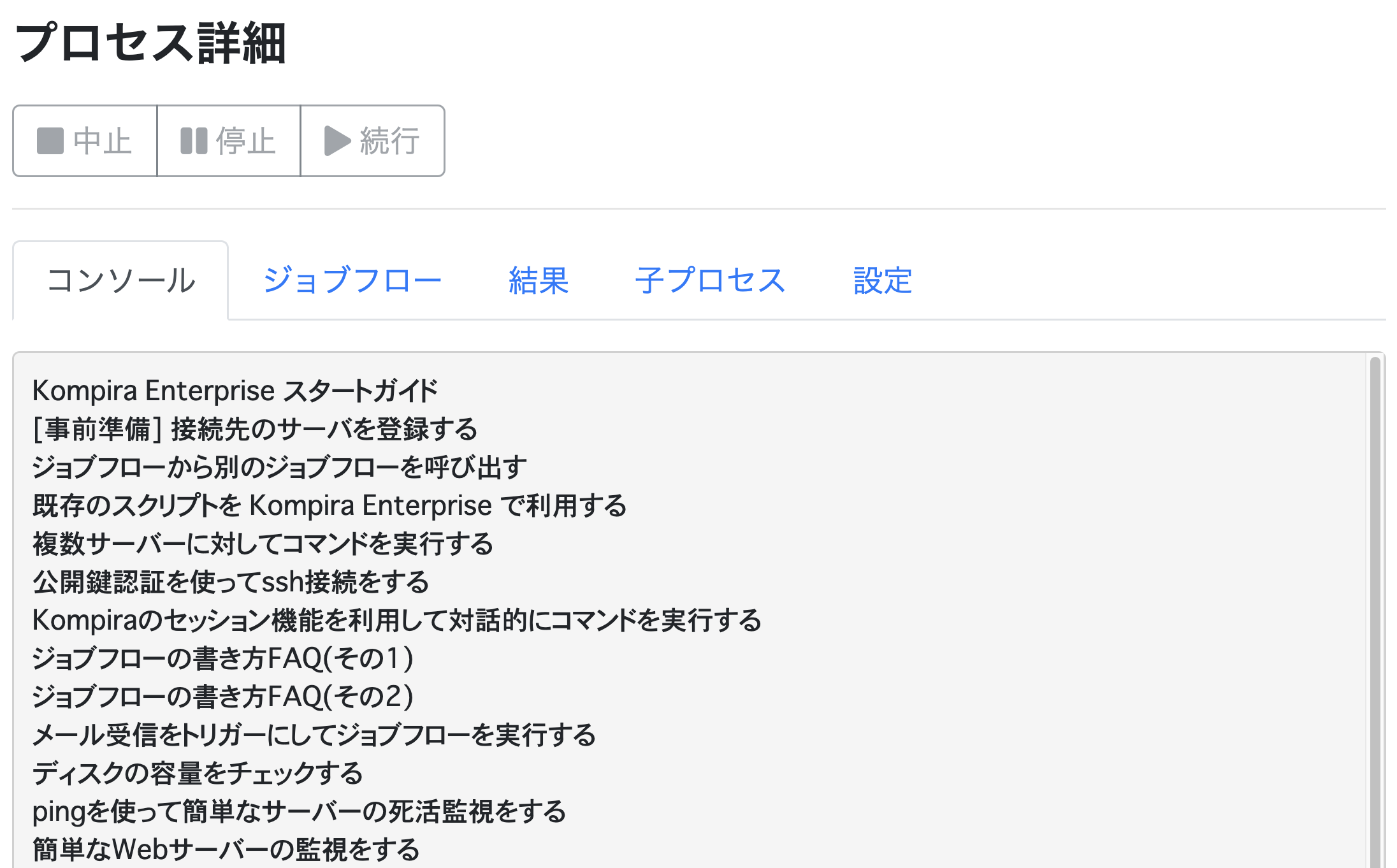
本稿では、コラムサイトの HTML リソースからタイトル一覧を取得しましたが、HTML リソース中の他のタグやクラスを指定することで、様々な情報を取得することができます。興味がある方は、オリジナルの Kompira Enterprise ライブラリを作成してみてください。