

みなさま、始めまして。
NTTコミュニケーションズの藤本と申します。
「Kompiraでオペレーションを標準化・高度化・効率化」というテーマでお話をさせていただきます。
よろしくお願いいたします。
私は統合ICT運用プラットフォームの「X Managed Platform(クロスマネージドプラットフォーム)」のサービス企画を担当しており、
X Managed PlatformとKompiraを組み合わせて、どういったことをしているかをご紹介をさせていただきます。
詳しい業務内容といたしまして、X Managed Platformに関しては直接外販をしているというわけではなく、我々がマネージドサービスプロバイダーとして運用サービスを受託している案件向けに開発をしているものになります。
X Managed Platformが目指している世界としては、サービスマネージャーやオペレーターの手を煩わせないオペレーションの実現、 つまりゼロタッチを目指していきたいと考えております。
運用業務(インシデント対応)における課題①
我々の運用サービスにおける課題をいくつかご紹介をさせていただこうと思います。
現在、環境観点においては監視対象が多様化してきています。
皆様もオンプレの機器に関しては言わずもがなと思いますが、クラウドが最近増えていることもご存じだと思います。
また弊社はキャリアなのでネットワークに強みを持っておりますので、SD-WANを入れたいであったり、コロナ化以降はリモートアクセスの需要が増え、SASEを導入したいという案件もあります。
そういったところで、それぞれ異なったもののメトリックを取っていきたいということがあります。
続いて、監視システムを案件ごとに作り込むのが大変ということです。
オンプレの機器だと、Pingや死活監視、SNMPをとりあえず監視システムに入れ込めば監視はできるといったところもあります。
しかし、「SD-WANのコントローラーで情報を見てください」、もしくは「API経由でアクセスをしてください」といったような製品が多数あります。
こういったところの仕組みを案件ごとにサービスマネージャーが作っていくのは、なかなか骨が折れる作業です。
運用業務(インシデント対応)における課題②
続いて、オペレーションにおける観点になります。
アラームが大量で取捨選択に時間がかかるということはよくあると思います。
中には1日に何万件も出るような案件もあります。
海外の拠点で品質が安定しておらず、頻繁にPingが欠ける等で時間がかかることがあります。
またオペレーターからすると、アラームがたくさん出るとどうしても漏れてしまうといったことが出てきます。
続いて、環境が多様化した結果、切り分けや状況確認に手間がかかるといった課題についてです。
オンプレの機器に対してリモートでSSHしコマンド叩くといったところから、ダッシュボードやグラフ等色々開く必要があり、どうしてもオペレーションに時間がかかり、通知が遅れてしまうということがあります。
通知条件も多様化しており、システムや拠点ごとに通知条件を細かく設定してほしいということがあります。
例えば、データセンターが落ちたらすぐ連絡が欲しいが、海外の品質が安定しないところはしばらく静観して1時間継続すれば連絡してほしい、といったような要望があります。
また”ACT/STANDBY”で機器があった場合、両方落ちたら連絡が欲しいだとか、ネットワークのトポロジーで上位下位装置があった場合、上位が落ちた時に出る下位のアラームを検知しても、故障通知は故障した機器だけにしてもらいたい、ということがあります。
通知自体も電話というのは高コストということで、社内向けにはなるべく電話はしたくありませんでした。
「X Managed Platform」での開発ポイント
これらの課題を踏まえ、我々がX Managed Platformを開発していく上でいくつかポイントを設けて開発を進めてまいりました。
1点目に、プロセスやシステムの構成を標準化をしていくこと。
2つ目に、標準化されたプロセスに基づいて自動化等の仕組み作りをしていくこと。
3つ目に、最終的なオペレーションに関してはチケットシステムに集約をして、オペレーターがいちいち監視装置NMSを見るというオペレーションをしないこと。
これらを踏まえて開発を進めてまいりました。
「X Managed Platform」標準構成
具体的なX Managed Platformの標準構成として監視の対象の装置があり、オンプレの機器やSD-WANの機器、クラウド等があります。
オンプレは基本的に死活監視やSNMPの取得といったところは、ZABBIXを採用して監視を行っています。
クラウドに関してはAWSのCloud WatchやAzureのAzure Monitor等クラウドネイティブな機能があるので、こちらから各種メトリックを取得します。
SD-WANに関してはAPIが用意されていることが多いので、API経由で情報を取ってくるといった仕組みを用意しています。
我々の場合だと、この仕組みに関してはAzure functionというような形で、関数型のサーバーレスと言われているプログラミングを使い情報を定期的に取得するといった仕組みづくりをしています。
ここをVM立ててというようなことになると、どうしても手間がかかりコストもかかるので、クラウドネイティブなところはそっちに寄せておくというような形にしております。
それぞれの監視装置からKompira AlertHubの方にWebhookで連携をしており、こちらでアラームのフィルタリング、取捨選択を行っています。
Kompira AlertHubでは”ACT/STANDBY”を見てフィルタリング/ハンドリングをしたり、上位下位を見てハンドリングをしたり、通知条件が即時なのか、しばらく待って通知をするのか等、このような制御も担っています。
ServiceNowとの連携
対応が必要なものはServiceNowの方にチケット起票での連携をしております。
弊社の場合、運用サービスにおいてはお客様のコンタクトポイントはService Nowに統一をしております。
よってチケット管理やお客様からいただく非監視の情報、構成情報等もServiceNowに集約しており、ServiceNowにWebhookでKompira AlertHubから情報連携をしています。
なぜServiceNowに集約しているかというと、例えばお客様が作業連絡している場合というは「通知する必要はないが、アラームが発生した旨をチケットに入れておきたい」、「作業連絡もらっているが、その後ずっと落ちたままだけど問題ないのか」といったようなことがあるので、一旦Service Nowに集約をしようとしてます。
もちろんやり方によってはKompira AlertHubが直接通知するということもできますが、弊社の場合だと一旦ServiceNowでハンドリングをするというような形にしています。
作業連絡もなく、インシデントといったようなことになれば通知が動いていくというような形になっています。
通知は定番のメールからKompira Pigeonでの電話、パトランプも使いたいというニーズがありますので、こちらも使う仕組みを用意しています。
これらの手段を使って実際に故障であれば、お客様に通知を行うといったフローを回しています。
その他自動化の仕組み
さらに自動化の仕組みも用意しており、弊社の場合はもともとAnsibleを利用していたので、AWXの基盤を用意しています。
チケット起票後に一次切り分け的な部分で状況確認をAnsibleのPlaybook経由で取得し、チケットに追記をする等の作り込みをしています。
すべて自動化を目指すべきところではあるんですが、まだそこは道半ばというところで、手動で切り分けかをPlaybookの形で選択できるようにしています。
オンプレ機器+SD-WAN監視案件

実際に案件に当てはめた時はどうなっているかというと、具体的な例としてオンプレミスのネットワーク機器とSD-WANを監視している案件をご紹介します。
こちらの案件は非常にアラーム数が多く、先月だと161万件で1日5万件程度アラームが出ている案件になります。
こちらも海外の拠点があるうえにSD-WANが入っており、あえて”SEVERITY”を調節し”INFORMATION”のレベルでも情報を上げているといったような事情があります。
とはいえ1日5万件以上のアラームが発生してますので、これをオペレーターが手で仕分けるといったことは困難だと思います。
そこでKompira AlertHubで必要なアラームを取捨選択し、お客様に「故障です」と通知をしています。これが102件あります。
よってオペレーターはこの102件だけ対応しているというような状況になっています。
苦労点

苦労点についてお話させて頂きます。
まずシステムを案件に渡してもなかなかワークしないということです。
こちらは大きく2つあると思います。
ZABBIXやAlertHubの設定はどうしたらよいのかという問題と、横展開はどうしていくべきかという問題です。
まず1つ目として、設定の周りに関しては弊社内でよく使ってる機器(CISCO、FortiGate等)に関しては開発チームでZABBIXのテンプレートを用意しています。
そういったテンプレートも活用しながら、案件を横断で導入を支援するチームを発足させ、彼らの方でサービスマネージャーにヒアリングをかけながら設定をしています。
ZABBIXの場合はパラメータシート、Kompira AlertHubも我々でヒアリングシートを作っており、受信スロットをどう入れて深刻度をどう変え、どこにアクションしてきます、といったことを用意し、こちらを埋めて設定を入れていくといったような営みをしています。
さらにService Now経由でSM(Service Manager)がZABBIXの設定を入れ込むという仕組みも今作っているところです。
こういった仕組みを使って、なるべく設定のハードルを下げていき、なお且つサービスマネージャーの皆さんにもZABBIXやAlertHubに慣れていってもらうというような施策を行っています。
2つ目の横展開の観点に関しては、AlertHubでインポート/エクスポート機能が実装されているので、こちらを利用し同じような設定を横展開しています。
またアジリティやレジリエンスの観点で、ほぼ全てのコンポーネントに関して弊社の場合はクラウド化を実施しています。
ただ、どうしても全てクラウド化していくコスト高になるコンポーネントが出てきてしまうので、このコンポーネントに関しては我々のデータセンター内にHCIの基盤のようなものを作り、自前のクラウドという形でリソースを払い出したりしています。
今後の我々の取り組みとしては、さらにコスト削減や構成の効率化を図ってコストを圧縮していきたいと思っています。
「X Managed Platform」の今後の展開
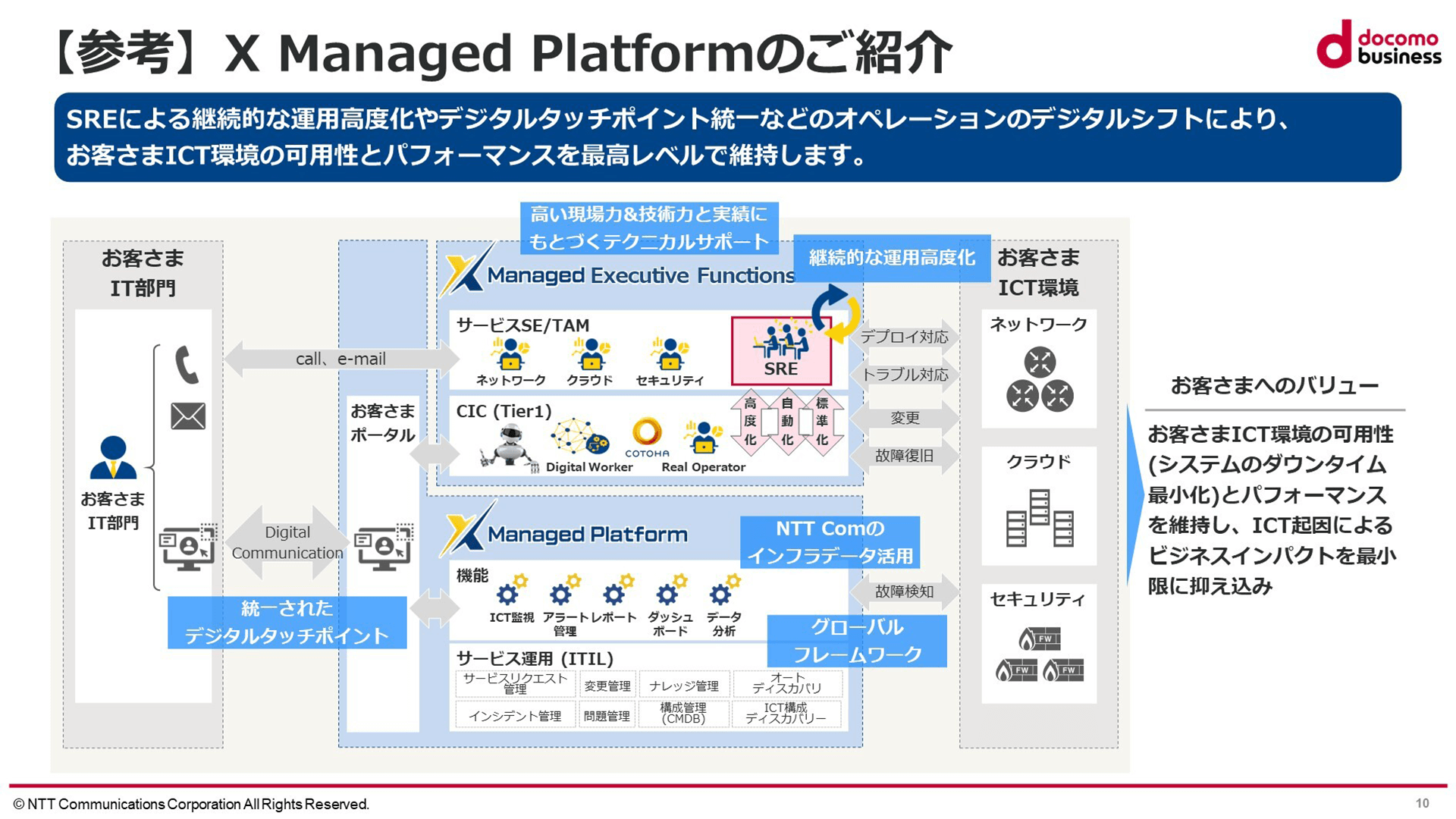
最後に、X Managed Platformのご紹介です。
例えばサービスマネージャーをアサインしたり、Tier1のオペレーターとして人をアサインしたり、AIを使いたい場合は「COTOHA」というAIのブランドがあるので、こちらを使うことができます。
その一方でSREというような提携作業の部分は、個社対応はもとよりSO(System Operation)作業、デリバリーや変更要求といった定型作業は非常に自動化しやすいところなので、Playbookを書いて継続的に運用を高度化していきましょうという取り組みを実施しています。
お客様に対してはクラウドやSD-WAN等のICT環境が幅広になってきていますが、こちらの可用性やパフォーマンスを最高レベルで提供することを目指しています。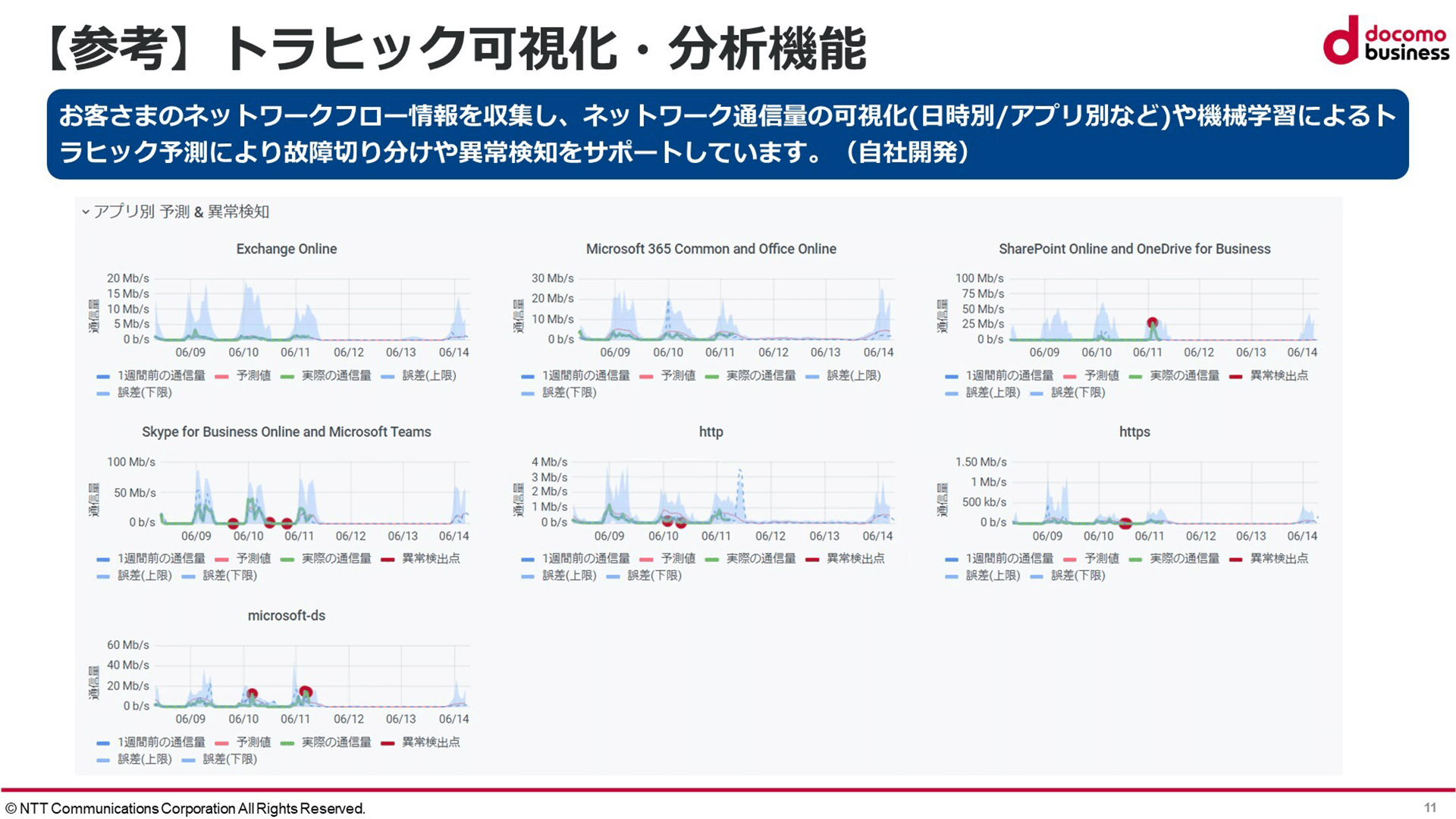
またネットワークフローの収集分析機能を持っており、どこの拠点からどういったプロトコル、通信が出ているかや、収集したトラフィックデータを元に機械学習で異常値を検出したり、トラフィック予想をするといったことができます。
またセキュリティ機能として、セキュリティ検知したらアラームが出たり、監視データのメトリックも収集してデータレイクに放り込んだ上で綺麗にクレンジング等を行い、お客様に月次レポートをご提供する等の取り組みを実施しております。
本日の私の発表は以上になります。
ご清聴ありがとうございました。








